Understanding Indexes in MySQL

Search for a command to run...
Is the indexing data structure same with NoSQL databases like Mongo db?
Good article for beginners, where everything is well explained. However it's hard to demonstrate the effectiveness of indexes on such small tables. Normally you wouldn't need an index for a table with less than one thousand records.
E.g. In my current job, I have a table with sales (one of many) in which I have at least eighteenth million headers per month. Which means that we have at least a total of 2 592 000 000 headers only. Imagine how many positions, products and payment records we have.
And to be honest you need to be extremely careful with indexes.
Because they not only increase storage, but degrade overall database performance while data grows.
One of the solutions is to move to Hadoop or Data Lake infrastructure or use horizontal scalable databases such as ScyllaDB or CockroachDB.
Thanks for the article. 🐬
PS: one thing that I saved in my brain, is that mysql can use only one index per table per query (I know there are some specials for joins and index merge)
It‘s a very good article. Showing benefits and shortcomings of the different types of indexes. Also the important note, that indexes come at a cost.
Thanks for writing.
Code reviews are an integral part of a developer's daily routine, ensuring the quality, correctness, and maintainability of the codebase. Whether you are requesting a review or providing one, adhering to best practices can significantly enhance the c...
As I sit on the swing at my home in Bangalore and chat with my brother, he tells me about a star gazing event his friends plan to visit near Mumbai. I have a sudden jump in my stomach, going to an astronomy camp is something I always wanted to do (st...
As I sit down on the swing planning for my trip to Mumbai and scrolling down through Instagram, I come across BombayBookies, a silent reading community based in Mumbai. I see their videos, and there is a sudden jump in my stomach; I wish I had Doraem...
Happy Teachers' Day to all the amazing teachers out there! Growing up, becoming a teacher was probably my dream profession. I was fortunate enough to have crossed paths with some truly remarkable teachers and mentors. Watching them, I always felt tha...
I have been drafting bits and pieces of this blog for around 6 months, finally putting everything together. I recently completed 3 years working as a Software Engineer at HackerRank; it has been an amazing journey filled with learnings, growth, chall...
I did something yesterday, which I never thought I would do. I did the Savandurga Trek. I had heard a lot about this trek being the most difficult one in Bangalore and I had made up my mind that I never would finish this. To give some context, I am b...

Indexes are important as our Database grows in size. We can consider Indexes as Keys that will help us perform faster lookups of rows. In this blog, we will understand the different types of Index in MySQL, their use cases, various strategies to decide the index for a table, and finally the benefits of having Indexes. So, let's get started.
This is the default type of Index in MySQL which is based on the B-Tree data structure.
The B-Tree index doesn't need a full table scan to find the desired data hence it speeds up the data access process. Similar to how a B-Tree works, in this index, the search starts from the root node and goes to the leaf node. Each node contains the minimum and maximum values for the child nodes. We find the right pointer by looking at these values and reaching the leaf node that has the pointer to the data needed. The depth of the B-Tree depends on how big our data is.
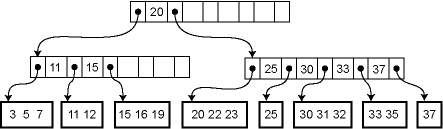
B-Tree stores the columns in an ordered manner which makes them useful for searching over a range of data, ORDER BY and GROUP BY operations.
B-Tree does a lookup from the leftmost indexed columns. Let's take an example to understand how adding a B-Tree Index will help us.
Consider the example of an Employee Database where we want to search for employees.
CREATE TABLE EMPLOYEE (
first_name varchar(40) not null,
last_name varchar(40) not null,
department varchar(40) not null,
joining_date date not null
);
Consider the following data inserted in the table,
| first_name | last_name | department | joining_date |
| Jaxon | Armstrong | Engineering | 2005-05-20 |
| Donna | Mckee | Sales | 2015-08-02 |
| Donna | Walton | Finance | 2005-01-10 |
| Donna | Hardy | Engineering | 2023-05-20 |
| Donna | Benton | Product | 2010-07-28 |
| Donna | Sawyer | Sales | 2005-03-29 |
| Donna | Schaefer | Finance | 2019-01-18 |
| Donna | Bauer | Engineering | 2020-09-14 |
| Tomas | Pennington | Engineering | 2019-05-20 |
Now that we have the schema defined, let's try to search for some Employees in the table and understand how the indexes can be defined and used.
ALTER TABLE EMPLOYEE (
ADD INDEX first_name,
ADD INDEX department,
ADD INDEX joining_date
);
Query 1:
SELECT * FROM EMPLOYEE WHERE first_name = 'Donna' and department = 'Engineering'
-- Uses the Index on first_name
Even though there is an Index on the department column, we only use the index on first_name as the three individual indexes act as three separate tables.
Now when we run this query, MySQL will have to scan across 7 rows where the first_name is Donna, imagine the same scan across a huge table where around 1 million people have a similar name. Adding a single-column index won't help a lot.
ALTER TABLE EMPLOYEE (
ADD INDEX (department, first_name, joining_date)
);
The following table contains a composite index on (department, first_name, joining_date).
Query 1:
SELECT * FROM EMPLOYEE WHERE department = 'Engineering' AND first_name = 'Donna'
-- Uses the Index on (department, first_name)
As compared to single column index, this will be faster as the number of rows to scan will get decreased by using the composite index on (department, first_name)
Query 2:
SELECT * FROM EMPLOYEE WHERE last_name = 'Hardy'
-- Doesn't use any Index
Query 3:
SELECT * FROM EMPLOYEE
WHERE first_name = 'Donna'
AND joining_date > 2010-07-28
-- Doesn't use any Index
-- since the lookup follows the leftmost side of indexed columns
-- we are not mentioning the department
-- hence composite index is of no use
Query 4:
SELECT * FROM EMPLOYEE
WHERE department = 'Engineering'
AND first_name LIKE '%S%'
AND joining_date = 2010-07-28
-- Uses the Index on (department, first_name)
-- since for first_name we have a range query
-- it will only use first two columns of index
In the case of using indexes for range queries, we should try using the range condition field last in the index. This is because after applying the range query there is no way for the B-Tree to apply the next filter, hence we should keep the range condition column at last.
For the Multi-column Indexes in this Table, we have index search capabilities on (department), (department, first_name) and (department, first_name, joining_date)
Consider the following query
SELECT * FROM EMPLOYEE WHERE department = 'Engineering' ORDER BY last_name
This will use the department index to give us the records, and then perform a sort on the records to sort them by last_name. This is because we didn't have any index on last_name hence the records were not sorted by that column. This type of sort fetches the data in a temporary buffer before returning it (File Sort) which leads to extra computation.
This can be avoided by adding an index on last_name. The new composite index for us would be (department, first_name, joining_date, last_name)
Proper Indexing also helps in GROUP BY operation.
Consider an example like
SELECT * FROM EMPLOYEE WHERE department = 'Engineering' GROUP BY first_name
The records would already be sorted department hence speeding up the filtering. After these results are returned they are also then sorted by first_name due to the second part of the index, and so they are already grouped for us. This won't require any other sorting hence making our query fast.
Index selectivity is the ratio of a number of distinct indexed values(cardinality) to the total number of rows in the table(#T). The range for selectivity is from 1/#T to 1.
An index is said to be highly selective if for each value we have fewer rows. Having a highly selective index is good as it filters out more rows when searching for query matches.
Now that we have understood what Index Selectivity is, let's see how it helps in deciding the column order.
Consider the same Employee Table Schema with the multicolumn index on (department, first_name, joining_date, last_name) . This composite index will perform better than a single column on queries but let's check if this is the perfect column order for the given set of values in the Employee Table.
Firstly, let's check the Index Selectivity of each of the four columns,
first_name: 3/9 = 0.33
Department: 4/9 = 0.44
last_name: 9/9 = 1
Since joining_date is a date field and we might want to do range queries on it, it is good to have it last in the order of index.
Based on the Selectivity, the ideal order looks like this (last_name, department, first_name, joining_date).
If we see the Query Examples above the initial order we defined works well for us as we can use Indexes for most queries. Hence along with selectivity, the use case of the WHERE clause also matters.
In Conclusion, the Index order for the Multi-Column Index depends on:
WHERE conditions to effectively lookup data
Use of ORDER BY and GROUP BY
Use of Range conditions in the query
Index Selectivity when unsure about the column order
The columns we want to SELECT in the Query
It is important to note that the indexes shouldn't be optimized only for the WHERE clause but for the entire query.
Hash Indexes are used when we want to do exact lookups on every column in the table. Hash codes are generated for each row on the indexed columns. Since the original values are converted to short values based on the hash function, they are compact.
In the case of Hash Indexes, the index contains only pointers to the values rather than the entire values, hence MySQL uses the in-memory rows to fetch the values from the pointers.
Some of the drawbacks of Hash Indexes are
Since we are generating Hash using a function, we can't use it for partial matching of values. Example: If we have an Index on (A, B), we can't use this Index in a query that only uses column A.
In case of two or more rows having the same values for a column, when generating the Hash Index, it will lead to a collision. In such a case, the engine will traverse all the row pointers and read the values for comparison to find the right value leading to extra computation.
Hash Indexes are not very useful for columns that have low selectivity since they will lead to hash collisions.
They can't be used for sorting because they don't store rows in a sorted fashion.
In the InnoDB storage engine when the values are being used frequently it creates a hash index on top of the B-Tree Index which leads to faster lookups. This is known as adaptive hash indexes.
Some other available Index Types include the Spatial Index which is used for geometry and geography types and Full-text Indexes which split the text into words and make an index over the words and not the whole text. This works faster for text searches when looking for specific words.
The benefits of indexing are measured on the three-star system
One Star if the Index reduces the rows that we have to scan.
Two Star if it improves performance by removing the overhead of sorting and temporary tables.
Three Star if all the required columns for querying are a part of the index.
MySQL can use columns only if they are isolated in the query. We should avoid using functions in the WHERE clause.
Bad Query:
SELECT * FROM EMPLOYEE
WHERE department = 'Engineering'
AND YEAR(joining_date) = 2010
The above query will only use the index department even though an index is present on joining_date. This is because we have enclosed joining_date within a function.
In the case of multiple single-column indexes, MySQL sometimes uses multiple indexes by performing Index Merge. But it is not efficient since in the case of OR conditions, operations like sorting, grouping can utilize a lot of resources. In the case of AND conditions, it makes more sense to use a multicolumn index over multiple single-column indexes.
Indexes are implemented at the storage engine level and not the server level, hence differs from engine to engine.
Even though we use an ORM, we can't rely on it for indexing as they usually generate queries that satisfy the underlying logic.
Indexes come with drawbacks as well. There is a performance impact on INSERT, UPDATE, and DELETE operations. Every time we perform a write on a table, the indexes have to be maintained. Hence, it's important to choose Index wisely.
Always Test the indexes on the queries the application is performing by measuring the response time.
Using the EXPLAIN statement to understand how the query is executing and reveal why it is slow. Explain statement shows values such as the indexes used, order used for joining the table, rows accessed, use of Filesort or not, and a temporary table used or not.
I hope this article helps you in starting to use Indexes in your MySQL Databases.