Last month when I was back at my hometown & on-call simultaneously, I got an alert from OpsGenie at 4:30 am. The alert was loud enough to wake everyone up. Everyone was curious about who was calling this early so I explained to them that it was a bug in my code alerting me. The immediate question was why an error in the code had to give me a call when it was occurring.
Now to explain it, the simplest analogy I could think of was of a fire-fighter. Similar to how when a fire happens, the fire alarm alerts the fireman, similarly in the case of software engineering, the bug is the fire, the call is the fire alarm & I am the firefighter.
In recent months, I have been trying to set up the on-call process in my team & this blog post, we will be breaking down and understanding what the on-call process looks like and what are some of the things to keep in mind when setting up the process.
Firstly, let's understand why a developer needs to be on-call. This is something I read about the practice that is followed at PagerDuty, "you build it, you own it". Since developers usually want the flexibility to deploy to production whenever they want, they being the subject matter experts on the code, should be the ones taking ownership of any alerts. It's a practice that is followed where SREs/DevOps Engineers are usually responsible for the infrastructure (hardware, databases) while the Developers are responsible for everything built on top of it. This responsibility division is usually followed in most of the organizations but may vary depending on the team size & the organization structure.
Now that we have understood why a developer needs to be on-call, let's break down the on-call process.
Setting up Alerts
This is the most essential step in starting your on-call process. The main goal of this step is to identify the most crucial services, which if down, can disrupt the user experience or indicate some fault in the infrastructure which may not be impacting the user directly but has some indirect effect on the overall functioning of the product. One of the important things to keep in mind is to avoid alert fatigue i.e. making sure the alerts are fewer by removing unactionable/unwanted alerts. This is something that gets better over time by experimentation. One of the ways to check if the experimentation is working or not is to see the trend of alerts over time.
Multiple apps might be used like New Relic, Sentry, and HoneyBadger but it is always recommended to redirect all the alerts from different platforms to one alert management tool (OpsGenie/PagerDuty).
Setting up the OnCall Schedule
When it comes to on-call schedules, there's no one-size-fits-all. The schedule varies from team to team. For teams that are spread across geographies, teams usually adhere to a follow-the-sun process where people have to be on call only during the day & as the day sets, team members from the other end of the geography take charge of on-call. In cases where the team is in the same geography, the team members are on-call for both day & night but might vary from team to team.
One of the things to note is to encourage people on-call to swap their schedules with other teammates if they are available in case of emergency/travel plans so that they can try to maintain their regular schedule as much as possible. When doing so it is important to update the alert management system to make sure all alerts are redirected to the right person.
Remember, that on-call can sometimes be tiring for the engineer & hence it is recommended to relax or swap hours in between.
Escalation Policy
There are times when the on-call engineer might not be able to acknowledge an alert due to various reasons like being AFK, or internet issues. In such cases, having an escalation policy helps.
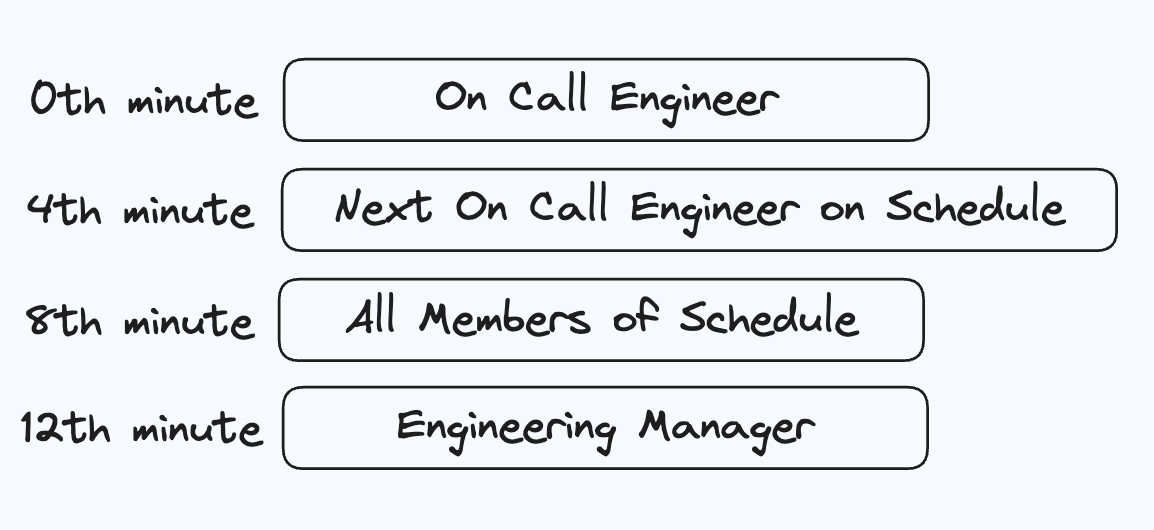
This is what a sample escalation policy looks like. At the 0th Minute, that is when the alert occurs, the on-call engineer is notified. If the alert stays unacknowledged till the 4th minute after the alert occurred, the next on-call engineer will be alerted, and so on.
The escalation policy can again be modified from team to team based on the requirements.
Now that we have understood how to set the on-call process, let's understand the process during an outage.
During an Outage
When the Alarm Rings: The Act of Acknowledgment and Assessment
At the heart of on-call, acknowledging an alert is the first move. The on-call engineer becomes the first responder, swiftly assessing the severity and impact of the alert. The key here is to stay calm. It is recommended to document the severity criteria (P0 - entire site down, P1 - some parts not functioning) so that the on-call engineer can map the alert to severity & respond. This is called Triaging.
Inform and Mobilize: The Symphony of Stakeholder Communication
With the facts in hand, it's time to inform the right stakeholders. Communication is key, and orchestrating it effectively ensures everyone is on the same page. This usually involves keeping the customer-facing & engineering teams in the loop with the progress of the outage. Try keeping the appropriate channels of communication updated. It can also be in the form of JIRA tickets with relevant data, graphs, and CLI outputs.
Seeking a Lifeline: Collaboration in War Rooms
For complex issues, enter the war room—a collaborative space where different engineers unite to tackle the problem head-on. Seeking help is not a sign of weakness but a strategic move towards resolution. This also involves getting direction on the outage from the subject matter experts.
Mitigate, Don't Muddle: The Art of Temporary Fixes
In the heat of the moment, the goal is clear: mitigate the damage and restore functionality. Avoid fixing what's in production; instead, return to the last known stable state. Remember to never fix code when an outage is going on.
Root Cause Quest: Don't Dilly-Dally, But Don't Rush
Once the mitigation is done, follow the structured approach that involves finding the root cause first, fixing it to the core & ensuring a more stable foundation for the future.
Testing, Deployment, and the Healing Process
Don't bypass testing and deployment practices in the aftermath. Learn from the incident, implement preventive measures, and fortify your defenses against future disruptions.
Closing the Curtains on Chaos: When the Root Cause is Resolved
An outage can be considered resolved when all the alerts are back to normal & we see that the product is behaving expectedly for all the customers. It is important to note that an outage is considered resolved not after mitigation but once the permanent fix is in production.
The Post-Incident Analysis: A Blameless Review
As a last step, it's time for Root Cause Analysis (RCA) with a blameless mindset. Answer the quintessential who, what, where, when, and why to extract meaningful insights. It is in this step that we can document what went good/bad & what can be improved further with the next steps.
Metrics to look at
Now that we know how to respond to an alert, some of the metrics that can help us understand how the on-call process metrics of the team are
MTTA (mean time to acknowledge) is the average time it takes from when an alert is triggered to when work begins on the issue. This metric is useful for tracking your team’s responsiveness and your alert system’s effectiveness.
MTTR (mean time to resolve) is the average time it takes to fully resolve a failure. This includes not only the time spent detecting the failure, diagnosing the problem, and repairing the issue but also the time spent ensuring that the failure won’t happen again.
I hope this article helps you in understanding the on-call process better.
